

GraphQL is a query language inspired by the structure and functionality of online data storage and collaboration platforms Meta, Instagram, and Google Sheets. This post will show you how to take advantage of one of its soft spots.
Development
Facebook developed GraphQL in 2012 and then it became open source in 2015. It’s designed to let application query data and functionality be stored in a database or API without having to know the internal structure or functionality. It makes use of the structural information exchanged between the source and the engine to perform query optimization, such as removing redundancy and including only the information that is relevant to the current operation.
To use GraphQL, since it is a query language (meaning you have to know how to code with it), many opt to use a platform to do the hard work. Companies like the New York Times, PayPal, and even Netflix have dipped into the GraphQL playing field by using Apollo.
Apollo
Apollo Server is an open-source, spec-compliant tool that’s compatible with any GraphQL client. It builds a production-ready, self-documenting GraphQL API that can use data from any source.
Apollo GraphQL has three primary tools and is well documented.
- Client: A client-side library that helps you digest a GraphQL API along with caching the data that’s received.
- Server: A library that connects your GraphQL Schema to a server. Its job is to communicate with the backend to send back responses based off the request of the client.
- Engine: Tracks errors, gathers stats, and performs other monitoring tasks between the Apollo client and the Apollo server.
(We now understand that GraphQL is query language and Apollo is spec-compliant GraphQL server.)
A pentester’s perspective
What could be better than fresh, new, and developing technology? Apollo seems to be the king of the hill, but the issue here is the development of Apollo’s environment is dynamic and fast. Its popularity is growing along with GraphQL, and there seems to be no real competition on the horizon, so it’s not surprising to see more and more implementations. The most difficult part for developers is having proper access controls for each request and implementing a resolver that can integrate with the access controls. Another key point is the constant new build releases with new bugs.
Introspection
Batch attacks, SQLi, and debugging operations that disclose information are known vulnerabilities when implementing GraphQL. This post will focus on Introspection.
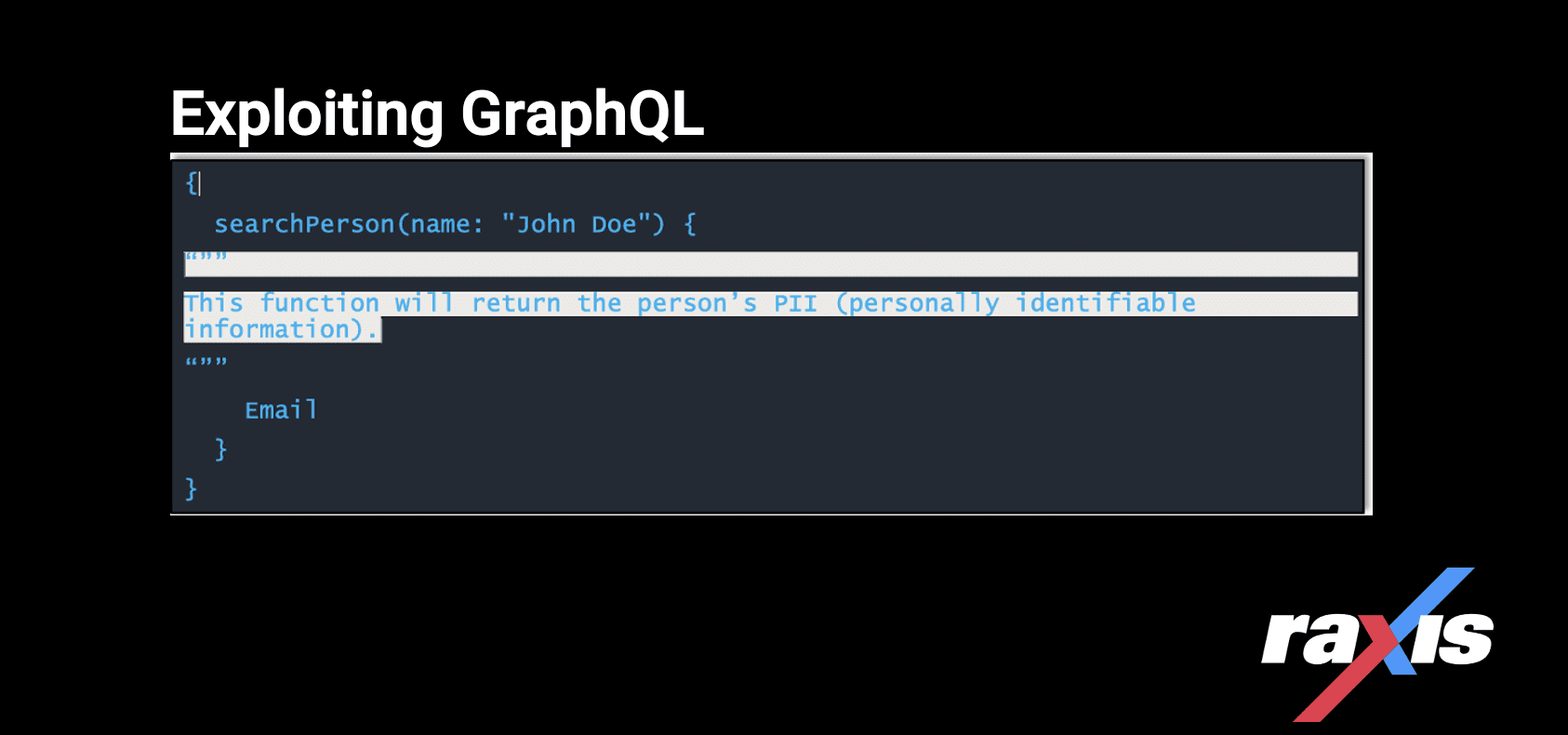
Introspection enables you to query a GraphQL server for information about the schema it uses. We are talking fields, queries, types, and so on. Introspection is mainly for discovery and as a diagnostic tool during the development phase. In a production system you usually don’t want just anyone knowing how to run queries against sensitive data. When they do, they can take advantage of this power. For example, the following field contains interesting information that can be queried by anyone on a GraphQL API in a production system with introspection enabled:
Let’s try it
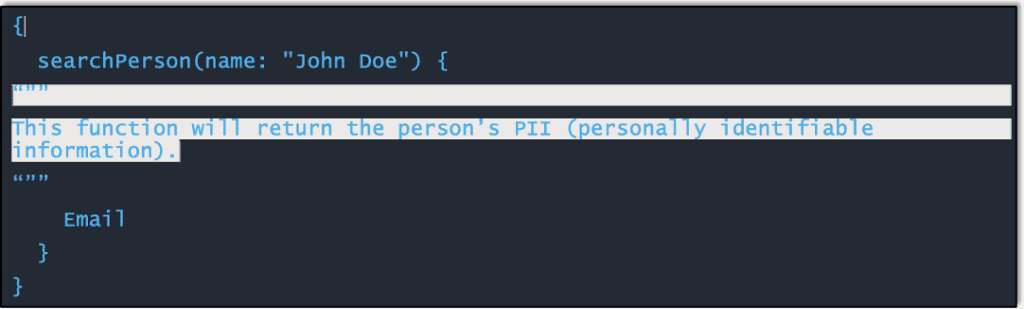
One can obtain this level of information in a few ways. One way is to use Burp Suite and the GraphQL Raider plugin. This plugin allows you to isolate the query statement and experiment on the queries. For example, intercepting a post request for “/graphql”, you may see a query in the body, as shown below:
Using Burp Repeater with GraphQL we can change the query located in the body and execute an Introspection query for ‘name’ and see the response.
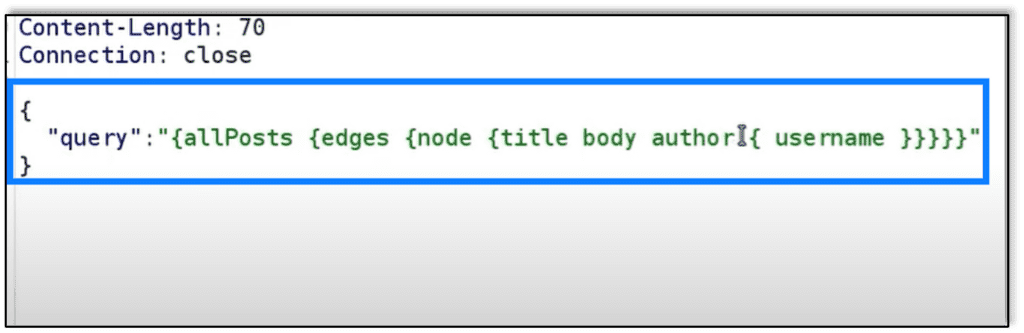
Knowing GraphQL is in use, we use Burp Extension GraphQL Raider to focus just on queries. Here we are requesting field names in this standard GraphQL request, but this can be changed to a number of combinations for more results once a baseline is confirmed.
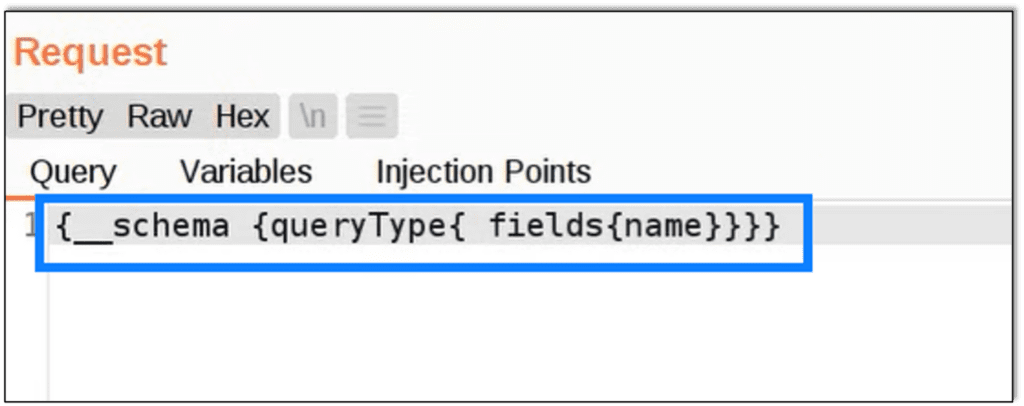
This request is checking the ‘schema’ for all ‘types’ by ‘name’ . This is the response to that query on the right.
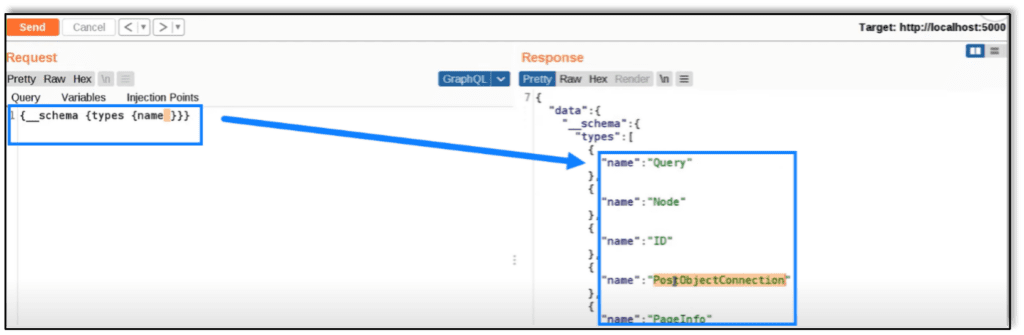
Looking further into the response received, we see a response “name”: “allUsers”. Essentially what is happening is we are asking the server to please provide information that has “name” in it. The response gave a large result, and we spot “allUsers”. If we queried that specific field, it would likely provide all the users.

The alternative would be to use CURL. You can perform the same actions simply by placing the information in a curl statement. So the same request as above translated over for Curl would be similar to:

You could opt to do this in the browser address bar as well, but that can be temperamental at times. So you can see how easy it is to start unraveling the treasure trove of information all without any authentication.
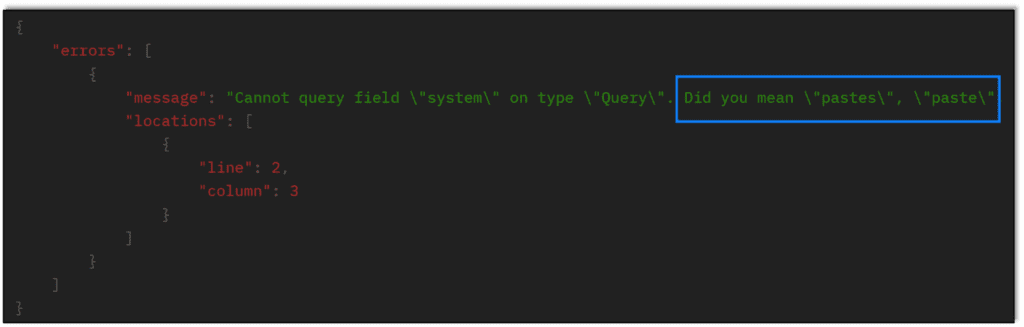
Even more concerning are the descriptive errors the system provides that can help a malicious attacker succeed. Here we use different curl statement to the server. This is the same request except that the query is for “system.”

When the request cannot be fulfilled, the server tries its best to recommend a legitimate field request. This allows the malicious attacker to formulate and build statements one error at a time if needed:
Pentest ToolBox
Ethical hackers would be wise to add this full request to their toolbox as it should provide a full request that provides a long list of objects, fields, mutations, descriptions, and more:
{__schema{queryType{name}mutationType{name}subscriptionType{name}types{...FullType}directives{name description locations args{...InputValue}}}}fragment FullType on __Type{kind name description fields(includeDeprecated:true){name description args{...InputValue}type{...TypeRef}isDeprecated deprecationReason}inputFields{...InputValue}interfaces{...TypeRef}enumValues(includeDeprecated:true){name description isDeprecated deprecationReason}possibleTypes{...TypeRef}}fragment InputValue on __InputValue{name description type{...TypeRef}defaultValue}fragment TypeRef on __Type{kind name ofType{kind name ofType{kind name ofType{kind name ofType{kind name ofType{kind name ofType{kind name ofType{kind name}}}}}}}}
Ethical hackers, may want to add these to their directory brute force attacks as well:
- /graphql
- /graphiql
- /graphql.php
- /graphql/console
Conclusion
Having GraphQL introspection in production might expose sensitive information and expand the attack surface. Best practice recommends disabling introspection in production unless there is a specific use case. Even in this case, consider allowing introspection only for authorized requests, and use a defensive in-depth approach.
You can turn off introspection in production by setting the value of the introspection config key on your Apollo Server instance.

Although this post only addresses Introspection, GraphQL/Apollo is still known to be vulnerable to the attacks I mentioned at the beginning – batch attacks, SQLi, and debugging operations that disclose information – and we will address those in subsequent posts. However, the easiest and most common attack vector is Introspection. Fortunately, it comes with an equally simple remedy: Turn it off.

About The Exploit
The Exploit is written by Raxis penetration testers. Every post is a technical writeup from someone who runs engagements for a living, with code, command output, and the reasoning behind each step. Topics include exploit research, vulnerability disclosure, tool development, and the offensive techniques showing up in current client work.
Search The Exploit Blog
Raxis Discovered Vulnerabilities
View the CVEs and bugs that Raxis pentesters have uncovered and submitted.
Work With the Pentesters Who Wrote This Blog
The engineers behind these posts run real engagements every week. Put them on your network, web apps, APIs, or cloud and see what an attacker would find first.
Blog Categories
- AI
- Careers
- Choosing a Penetration Testing Company
- Exploits
- How To
- In The News
- Injection Attacks
- Just For Fun
- Meet Our Team
- Mobile Apps
- Networks
- Password Cracking
- Patching
- Penetration Testing
- Phishing
- PTaaS
- Raxis Discovered Vulnerabilities
- Raxis In The Community
- Red Team
- Security Recommendations
- Social Engineering
- Tips For Everyone
- Web Apps
- What People Are Saying
- Wireless
