


Local privilege escalation bugs in the Linux kernel keep showing up, and the pattern is familiar. An attacker gets code execution inside one of your containers through a web RCE, a poisoned dependency, or a misconfigured service. From there, a kernel bug turns that foothold into root on the host, and on a shared-kernel cluster – that can mean access to other tenants’ workloads.
Two recent disclosures, Copy Fail and Dirty Frag, illustrate the pattern well. This guide will use them as concrete examples. But the real point of this guide is the defensive architecture, because the same playbook protects you against the next bug in this class, even when it hasn’t been disclosed yet.
Key takeaways
- Patching always lags: Kernel bugs go public and get weaponized before fixes reach your nodes, so architecture must cover the gap.
- Don’t share a kernel with untrusted workloads: Fargate, gVisor, and Kata Containers isolate the kernel per task or pod and prevent a complete takeover of the application from a single bad component.
- Cut kernel attack surface with seccomp and AppArmor/SELinux: Deny AF_ALG sockets, unprivileged user namespaces, and splice primitives most workloads never use.
- Harden containers: Set directives like runAsNonRoot, readOnlyRootFilesystem, and drop all capabilities. Also consider shipping distroless or scratch images so page-cache-poisoning exploits find no setuid binaries to corrupt.
- Detect at two layers: WAF or IPS for the initial RCE, behavioral runtime tools like Falco or Tetragon for the privilege escalation that follows.
Two Recent Examples of the Same Class of Bug
Copy Fail (CVE-2026-31431), disclosed April 29, 2026, abuses the kernel’s Crypto API through the AF_ALG socket family. An unprivileged user performs controlled 4-byte writes into the page cache, which is where Linux keeps in-memory copies of files. By overwriting the cached version of a privileged binary like su or sudo, the attacker waits for any privileged process to run the corrupted version and rides that into root. It affects nearly every distro shipping a kernel built since 2017, and CISA has added it to the Known Exploited Vulnerabilities catalog.
Dirty Frag, disclosed May 7-8, 2026, chains two separate bugs in the xfrm-ESP and RxRPC subsystems. splice(2) pins a page-cache page into a pipe buffer, then the kernel’s IPsec or RxRPC decryption code does in-place decryption on those splice-pinned pages. The decryption writes back over the original file content in the page cache, ignoring write protections. Working exploit code is public, the embargo broke early, and Linux distributions did not have time to patch before exploits were happening in the wild.
Critically, the algif_aead blacklist that mitigated Copy Fail does nothing to mitigate Dirty Frag because it’s a different point in the kernel and a different syscall path. This is exactly why defense in depth matters: a single mitigation tied to one CVE leaves you exposed to the next bug that walks a different path to the same outcome.
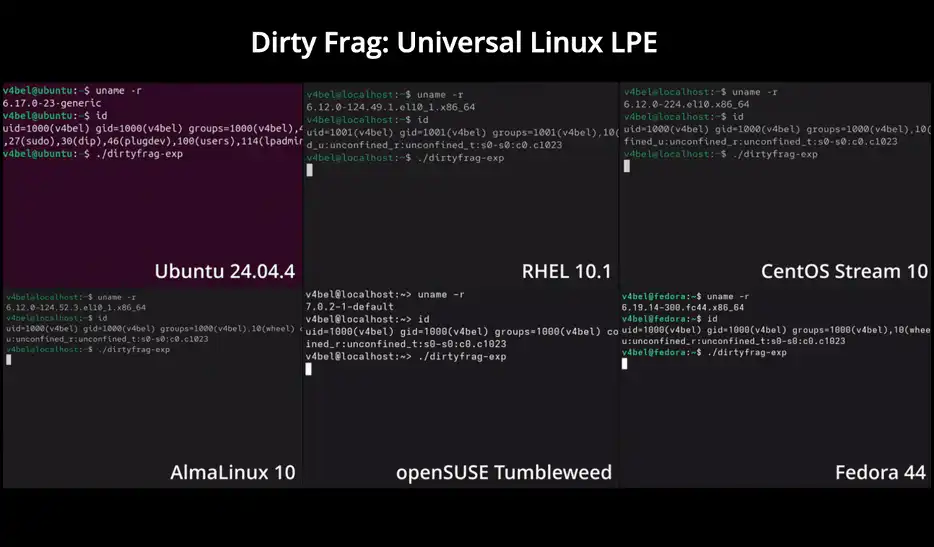
Both are local privilege escalations. Both need code execution somewhere on the host first. Both abuse legitimate kernel features that most workloads don’t actually use. That last piece is what makes it easier to defend against.
The Threat Model You’re Actually Defending Against
Anything that gives an attacker code execution inside one of your containers becomes a path to host root, and from there potentially to other tenants on the same node. A web RCE in a Node.js service becomes a kernel exploit becomes full cluster compromise.
The defensive question isn’t how do I patch this specific bug? The right question is: how do I architect things so that an unpatched kernel bug can’t actually be exploited from inside my workloads?
A clarifying note on what the strategies below actually do. Most of them do not fix the underlying kernel vulnerabilities. The kernel remains vulnerable. What these defenses remove is the path an attacker uses to reach the bug: the syscalls they call, the modules they load, the binaries they corrupt, or, in some cases, the shared kernel itself. The bug is still there. The exploit just can’t get to it from where the attacker stands.
Strategy 1: Stop Sharing a Kernel With Untrusted Workloads
This is the highest-leverage architectural decision, and the correct approach depends on your stack.
AWS Fargate runs every task on a dedicated Firecracker microVM with its own kernel. A kernel exploit inside the container reaches a kernel that no other tenant shares. The blast radius is one task’s microVM rather than the whole node. Lambda uses the same model. Fargate also gives you no SSH access and no kernel module loading, which closes off two prerequisites these exploits commonly chain through.
The kernel inside that microVM is still potentially vulnerable. The point is that compromising it doesn’t give the attacker access to anything beyond their own task.
gVisor, which backs Google Cloud Run, intercepts syscalls in userspace and only forwards a vetted subset to the host kernel. Many of the kernel surfaces these exploits abuse, including AF_ALG sockets and certain splice patterns, simply aren’t reachable from inside a gVisor sandbox.
Kata Containers is the open-source equivalent if you run your own Kubernetes. Each pod gets a lightweight VM kernel. This means a kernel exploit inside one pod is contained to that pod’s guest kernel. The host kernel and other pods’ kernels are unaffected, so the exploit can’t pivot to the rest of the cluster through the kernel attack surface.
If you stay on vanilla EKS, GKE, or AKS with shared-kernel containerd, one rooted container can attack the host kernel directly. Everything below this section matters much more in that case.
Strategy 2: Reduce Kernel Attack Surface With Syscall Filtering
Both example exploits need specific kernel surfaces to work. Most workloads don’t need those surfaces, so take them away.
Seccomp profiles: Deny socket(AF_ALG, …) outright. Docker’s default profile does not block it. Kubernetes’ RuntimeDefault does on recent versions but verify to confirm your version’s status. CERT-EU has been recommending this for all containerized workloads regardless of patch status, since opening an AF_ALG socket is the first move of the Copy Fail exploit and several of its predecessors.
User namespaces: Dirty Frag’s ESP path requires unshare(CLONE_NEWUSER) from an unprivileged user. Ubuntu’s AppArmor profile blocks this by default. AppArmor or SELinux policies that prevent unprivileged user namespace creation cut off a path that many kernel exploits depend on.
Splice primitives: splice(), vmsplice(), and MSG_SPLICE_PAGES are zero-copy primitives that several recent exploits abuse, including Dirty Pipe from back in 2022. Restrict or deny them in workloads that don’t need them.
The pattern here applies broadly. When a kernel feature has a track record of showing up in exploit chains and your workload doesn’t need it, removing access is cheap insurance.
Strategy 3: Harden Containers to Make the Initial RCE Impractical
Kernel exploits only matter after an attacker gets code execution inside a container. Hardening the container won’t stop a Copy Fail or Dirty Frag exploit once an attacker is already running code, but it raises the bar for the RCE that has to land first. Most web RCE chains depend on writing files to disk, fetching a second-stage payload, or invoking shell-installed tools. Take those away and many off-the-shelf exploits stop working.
Standard pod security context, applied to every workload:
runAsNonRoot:true# forces the container to run as an unprivileged user, so a compromised process can’t write to root-owned paths.readOnlyRootFilesystem:true# blocks dropping a payload anywhere except explicitly mounted writable volumes.allowPrivilegeEscalation:false# sets the no_new_privs bit, neutering setuid binaries inside the container.capabilities.drop:["ALL"]# strips kernel capabilities; add back only what the workload actually needs.
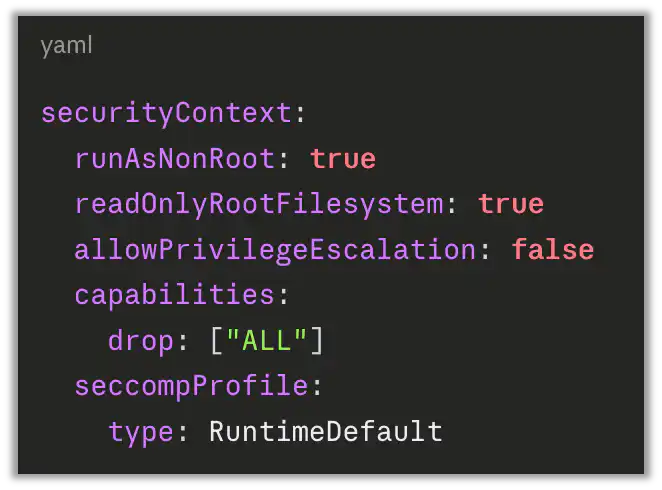
None of these stop a kernel exploit on their own. Together they shrink the attack surface and turn the first step of the chain into a dead end for many off-the-shelf exploits.
Strategy 4: Use Minimal Base Images to Eliminate Exploit Targets
This deserves its own section because it’s underused.
The Copy Fail exploit works by overwriting the in-memory page cache of privileged binaries like su or sudo and waiting for them to run. If those binaries don’t exist in your container, the in-container variant of that exploit has no targets to corrupt.
Real-world example: AlmaLinux 10 minimal and micro images ship without su, sudo, or other setuid binaries by default. A Copy Fail exploit running inside one of these images has no privileged on-disk binary whose page cache it can poison to escalate. The same logic applies to distroless images, scratch-based Go containers, and any base image that strips setuid binaries:

This is not a complete defense. An attacker can still target binaries mounted in from the host, executed via the host runtime, or shipped with applications that bundle their own setuid helpers. The kernel bug itself is still exploitable in principle. What you’ve done is remove the convenient targets, which forces the attacker to bring their own or find another path.
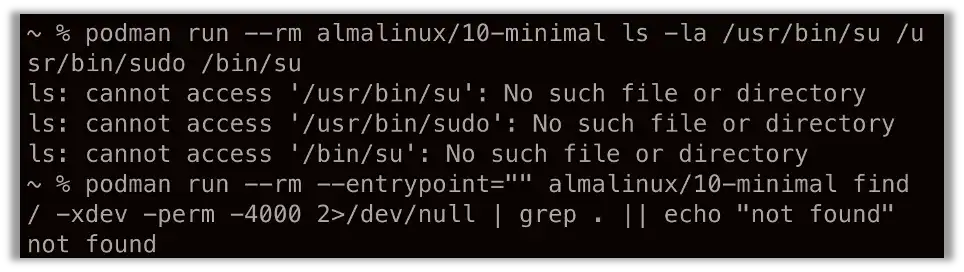
Often that’s enough to break a published exploit chain and stop unskilled opportunistic attackers from compromising your stack with a prebuilt script.
A word of caution though: if you use the minimal image, it does ship with microdnf. If coupled with network access, microdnf could be used to install a setuid binary like sudo, re-introducing the exploit target the minimal image was supposed to eliminate.
Even the micro image isn’t airtight. An attacker with write access and network egress could sideload a precompiled setuid binary using whatever the application itself provides for network IO (Python’s urllib, Node’s fetch, a Go HTTP client, etc.). However, this gets significantly harder if a read-only rootfs (Strategy 3) is paired with strict egress controls like Kubernetes NetworkPolicies, service-mesh egress rules, or a node-level egress firewall which prevent the container from reaching arbitrary hosts to fetch a payload.
Distroless Images Are the Gold Standard
If you want the strongest version of this defense, go distroless. Distroless images ship your application with its direct runtime dependencies and nothing else. No shell, no package manager, no coreutils, no setuid binaries, often not even a libc beyond what the app needs. An attacker with RCE inside one of these images has almost nothing on-disk to corrupt or pivot through.
A quick terminology note: no container image contains a Linux kernel. Containers always share the kernel of the host they run on. When people say “distroless,” they mean the image doesn’t ship a userspace Linux distribution. The kernel question is separate and is about your container runtime (Fargate, gVisor, Kata, etc.), which we covered earlier.
The main distroless options worth knowing, ordered from strongest to most established:
Scratch (FROM scratch in your Dockerfile or Containerfile) is the absolute minimum: an empty filesystem. You add only your binary and whatever it needs. For a statically-linked Go or Rust binary that calls a small set of syscalls and depends on nothing else, scratch is hard to beat. The attacker gets your binary and that’s it. No libc, no CA certificates, no /etc/passwd, no /bin/sh. If your app is a single static binary, this is the gold standard.

Chainguard Images (cgr.dev/chainguard/...) are the strongest practical option for everything that isn’t a static binary. They’re built on Wolfi, a Linux undistro designed specifically for containers, with no Debian or Alpine lineage. Chainguard rebuilds daily against the latest CVE fixes, which is a meaningful operational improvement over slower-moving alternatives. The naming reflects the lack of a parent distro: cgr.dev/chainguard/static, cgr.dev/chainguard/node, cgr.dev/chainguard/python, cgr.dev/chainguard/jdk. None ship a shell, a package manager, or setuid binaries. For most teams running interpreted runtimes in 2026, Chainguard is the right answer.
Google Distroless (gcr.io/distroless/...) is the original distroless project and the one that is most widely deployed today. The naming is slightly misleading: images like gcr.io/distroless/nodejs22-debian12 are built from Debian packages, but they don’t ship a Debian userspace. The -debian12 tag indicates which Debian release the included libraries were sourced from for CVE tracking, not that you’re getting a Debian system. There’s no apt, no dpkg, no /bin/sh, no coreutils. Variants include static-debian12 (~2 MB, for statically-linked binaries), base-debian12 (~20 MB, adds glibc and openssl for dynamically-linked binaries), nodejs22-debian12, python3-debian12, and java21-debian12. If you’re already running Google Distroless, the security properties are real, and you don’t need to switch. If you’re picking something new, Chainguard’s faster CVE turnaround may be a better default for your organization.
For most teams, the practical pick is scratch for statically-linked Go or Rust services and Chainguard for interpreted runtimes (Node, Python, Java). Either way, you’re shipping an environment where the page-cache-poisoning class of exploit has no off-the-shelf targets to hit.
Strategy 5: Plan for Detection at Multiple Layers
You will not prevent every exploit at the architecture layer. Plan for detection, and plan for it at more than one layer.
Perimeter (catch the initial RCE): The kernel exploit is the second stage. The first stage is whatever gives the attacker code execution: a web RCE, a vulnerable dependency, a deserialization bug. Block that, and the kernel bug never fires. CrowdSec is a solid open-source option here: a collaborative IPS that ingests web server and application logs, applies signature and behavioral rules, and shares signals across a community blocklist. Bouncers enforce at nginx, traefik, Cloudflare, or iptables. Commercial WAFs (Cloudflare, AWS WAF, Akamai) cover similar ground. The specific product matters less than having something at the perimeter looking for known exploit patterns.
Runtime (catch the privilege escalation): If the initial RCE gets through, Falco, Tetragon, and AWS GuardDuty Runtime Monitoring can flag behavioral signatures inside running containers without per-CVE rule updates. The Copy Fail pattern is distinctive: a non-root process opens an AF_ALG socket, splices a setuid binary into a pipe, and shortly after some process is running with euid 0 that shouldn’t be. The pattern that holds across this class of bug:
- Unusual syscall sequences from unprivileged processes,
- Sudden privilege jumps
- Unexpected access to crypto or networking subsystems.
Rules built around those patterns survive across CVE boundaries.
File integrity monitoring on /etc/passwd, /usr/bin/su, and /usr/bin/sudo has its place for the broader threat model, but page-cache exploits modify memory, not disk. On-disk hashes look fine throughout the attack. FIM will not catch this class. Detection has to be behavioral or memory-based.
The layering is what matters. Perimeter catches the obvious attempts. Runtime catches what gets through. FIM catches persistence. None is sufficient alone.
Patching Is Necessary, But It Will Always Lag
Every defense in this guide exists because patching alone is never going to be fast enough.
Both Copy Fail and Dirty Frag illustrate the problem. Copy Fail patches rolled out across the major distros (Debian, Ubuntu, AlmaLinux, Fedora, SUSE, Red Hat) on a staggered timeline over several days, with newer kernels in releases like Ubuntu 26.04 LTS unaffected from the start. Dirty Frag was worse: the embargo broke early, working exploit code was public before any CVE was assigned, the upstream ESP patch landed days later, and the RxRPC patch took longer still. For most teams running most distros, there was a window measured in days to weeks where the bug was public, exploited in the wild, and unpatched on their systems.
This is not unusual. It’s the normal shape of kernel disclosure. Embargoes break early. Patches land upstream and then take time to reach distro-stable kernels. Distro-stable kernels land in package repos and then take time to reach your nodes. Your nodes take time to drain, reboot, and rejoin the cluster. By the time the patch is actually running in production, days or weeks have passed since the exploit went public.
The architectural defenses in this guide are what cover you during that window. They’re also what cover you against the next bug, the one that hasn’t been disclosed yet, the one that won’t have a name when it shows up in your logs.
A kernel-isolating runtime like Fargate, gVisor, or Kata doesn’t care which CVE you’re worried about. A seccomp profile that blocks AF_ALG and unprivileged user namespaces blocks every exploit that needs those primitives, named or not. A distroless image with no SETUID binaries and no shell is hostile to whatever exploit chain shows up next, regardless of which subsystem it abuses. Egress restrictions that prevent sideloading hold across CVE boundaries. Behavioral runtime detection that flags unusual privilege transitions catches new exploits with no rule changes.
None of these eliminate the need to patch. Patching is still necessary, and automated node replacement (Karpenter, managed node groups with auto-update) is one practical way to make sure patches actually reach production rather than waiting on someone’s manual reboot during business hours. The argument here is that patching is the bottom layer, not the only one. If you treat it as the only one, you’re choosing to be exposed during every disclosure window for every kernel bug, indefinitely.
The teams that handle these disclosures calmly aren’t the ones with the fastest patching pipelines, though good pipelines help. They’re the teams whose architecture makes the average kernel CVE a non-event. Copy Fail and Dirty Frag are this month’s examples. Soon there will inevitably be another. The defenses don’t change.
Thanks for Reading
As a pentester at Raxis, I’ve had my share of debriefing calls with penetration test customers where we discuss why Raxis recommends hardening systems and services that should never be accessible to an attacker. These recent attacks are a clear example of why we recommend that.
You can’t know what 0day may appear tomorrow (or already did that you don’t know about yet), but you can lock down your networks in ways that encourage attackers to move along and look for an easier target before they gain access.
I hope you enjoyed this blog and that it helps your organization become more secure.

Ryan Chaplin
About The Exploit
The Exploit is written by Raxis penetration testers. Every post is a technical writeup from someone who runs engagements for a living, with code, command output, and the reasoning behind each step. Topics include exploit research, vulnerability disclosure, tool development, and the offensive techniques showing up in current client work.
Raxis Discovered Vulnerabilities
View the CVEs and bugs that Raxis pentesters have uncovered and submitted.
Work With the Pentesters Who Wrote This Blog
The engineers behind these posts run real engagements every week. Put them on your network, web apps, APIs, or cloud and see what an attacker would find first.
Blog Categories
- AI
- Careers
- Choosing a Penetration Testing Company
- Exploits
- How To
- In The News
- Injection Attacks
- Just For Fun
- Meet Our Team
- Mobile Apps
- Networks
- Password Cracking
- Patching
- Penetration Testing
- Phishing
- PTaaS
- Raxis Discovered Vulnerabilities
- Raxis In The Community
- Red Team
- Security Recommendations
- Social Engineering
- Tips For Everyone
- Web Apps
- What People Are Saying
- Wireless
